一、理论
1、ASCII:American Standard Code for Information Interchange, 美国信息交换标准代码。单字节编码,包含了大小写英文字母和一些符号。

ASCII是由 ANSI( American National Standard Institute 美国国家标准学会) 制定的。
2、ANSI 编码:因为单字符无法应对多个国家的编码,因此很多国家都对ASCII做了扩展,使用多个字节来编码,比如简体中文 GBK 和 台湾繁体 BIG5,这些编码被称为统称为 ANSI 编码。
ANSI 编码这个统称其实有些不恰当,因为他们不是ANSI制定的标准。只是因为是从 ANSI 制定的 ASCII 做的扩展,微软在 Windows 里面,就把这些统称为了 ANSI 编码。
话说,简体中文的叫做 GBK,嗯,就是 GUO BIAO KUOZHAN 的首字母,是 GB2312 的扩展。
参见:
https://en.wikipedia.org/wiki/Windows_code_page
https://docs.microsoft.com/en-us/windows/desktop/intl/code-pages
3、Unicode:是一个标准,我们可以只关注2个部分,字符集和编码方法。
其实在上面 ASCII 和 ANSI 时,没有区分过字符集和编码这两个概念,因为一个字符集就一个编码方法。但是在Unicode这里就不一样了,虽然字符集只有一个,编码方法有多种。
Unicode字符集:ANSI 编码存在一个问题,不同的语言存在不同的编码,一段二进制传过去,需要指定对应的编码,还要有对应的码表。所以,有一个囊括世界所有字符串的字符集就好了,那么就有了unicode字符集。unicode 字符集不断更新中,2018年5月发布的unicode 11.0 有 13.7 万的字符。
Unicode编码方法: Unicode TransferFormat,UTF8、UTF16 和 UTF32 等。
UTF8:变长编码方法,一个字节能表示就用一个字节,多个字节才能表示的话,就用第一个字节的第一个置位1来表示还需要后续字节。比较适合英文这种一个字节就能编码的场景。
二、Windows系统中的 codepage
在Windows系统上,使用了基于code page的字符集来实现不同的字符集,每个code page代表不同的字符集。code page 被分为 windows code page(也被称为 ANSI code page)和 OEM code page,后面用这种 codepage 实现的编码都被称为 ANSI 编码了。
不过不只是GB2312这种基于ANSI编码,UTF-7 和 UTF-8 也是采用code page 来实现的。chcp 命令可以显示和修改当前系统的code page。

936就是GB2312,在 XP 中控制面板也可以查看系统装的 code page,WIN7 里面没有了。
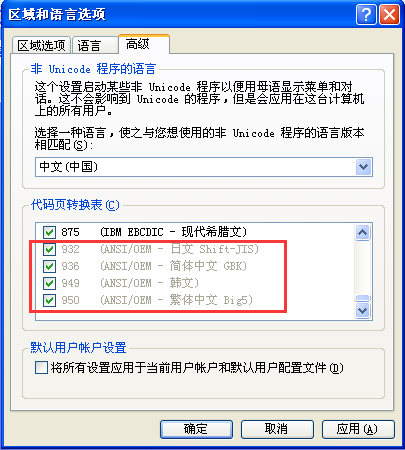
三、编码
1、W 和 A 的API之间的关系、使用 _T 和 L 的编码建议,略。
2、其他编码和UTF16之间的编码转换,使用 MultiByteToWideChar 和 WideCharToMultiByte。这里面的 WideChar 就是UTF16,函数名不如叫做 MultiByteToUTF16。使用时,要注意 CodePage 参数,其中 CP_ACP 就是系统当前的 codepage,不同系统的默认设置是不同的。曾经遇到过一个BUG,就是从UTF16转为多字节的时候,使用 CP_ACP 来作为参数,然后发送给后台处理,但是有的系统转的是中文默认的GBK,有的系统并不是,这里就有问题了。
3、MultiByteToWideChar 和 WideCharToMultiByte 使用起来真的比较麻烦,实际编程时一般使用 CW2A 和 CA2W 来转换。
ATL::CAtlStringW strTestW(L”测试”);
ATL::CAtlStringA strTestA = CW2A(strTestW, CP_UTF8);
使用时要注意他的生命周期,这东西其实是一个类,他析构了以后,返回的字符串指针也就是无效的了。
1、看下面一段代码,在中文系统中,使用VS调试的时候
ATL::CAtlStringW strTestW(L”测试”);ATL::CAtlStringA strTestA;strTestA = CW2A(strTestW, CP_UTF8); // 在VS中 strTestA 无法正常展示strTestA = CW2A(strTestW, CP_ACP);// 可以正常展示
因为系统把非Unicode编码的字符串都使用当前的字符集来显示的,中文系统默认是GB2312,所以显示乱码了,其实字符串里面存的东西是对的。
2、源文件和生成的二进制之间的关系。非 Unicode 编码时,VS尽量把字符串转换为ACP来编译。但是,但是,但是,这里只是尽量,还是跟文件编码,还有VS版本有关系,所以,我们干嘛要记住那么复杂的关系呢?我们老老实实用L的 UTF16 编码不就好了么?
3、书里面都是说 A 系列的API都是转换后调用的W系列API,我随手找了一个API,用IDA反汇编来看,为毛没看到 MultiByteToWideChar 的转换?
futh ojy more info